Algorithm - (12) 탐욕 알고리즘
1. 탐욕 알고리즘 이란?
Greedy algorithm 또는 탐욕 알고리즘 이라고 불리움
최적의 해에 가까운 값을 구하기 위해 사용
여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식
여러가지 경우의 수가 있을 때 각 단계마다 최적의 케이스를 선택하는 방식
2. 탐욕 알고리즘의 한계
- 탐욕 알고리즘은 근사치 추정에 활용
- 반드시 최적의 해를 구할 수 있는 것은 아니기 때문
- 최적의 해에 가까운 값을 구하는 방법 중의 하나임
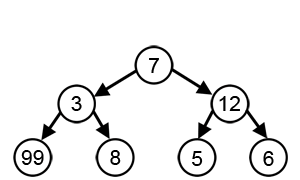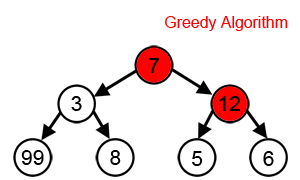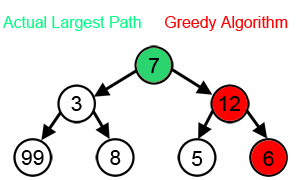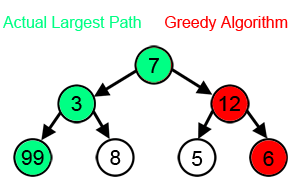
- ‘시작’ 노드에서 시작해서 가장 큰 값을 찾아 leaf node 까지 가는 경로를 찾을 시에
- Greedy 알고리즘 적용시 7 -> 12 -> 6 를 선택하게 되므로 7 + 12 +6 = 25 가 됨
- 하지만 실제 가장 큰 값은 7 -> 3 -> 99 이며, 7 + 3 + 99 = 109 가 답
3. 탐욕 알고리즘 예
동전 문제
- 지불해야 하는 값이 4720원 일 때 1원 50원 100원, 500원 동전으로 동전의 수가 가장 적게 지불하시오.
- 가장 큰 동전부터 최대한 지불해야 하는 값을 채우는 방식으로 구현 가능
- 탐욕 알고리즘으로 매순간 최적이라고 생각되는 경우를 선택하면 됨
Python
coin_list = [1, 100, 50, 500]
print (coin_list)
coin_list.sort(reverse=True)
print (coin_list)
coin_list = [500, 100, 50, 1]
def min_coin_count(value, coin_list):
total_coin_count = 0
details = list()
coin_list.sort(reverse=True)
for coin in coin_list:
coin_num = value // coin
total_coin_count += coin_num
value -= coin_num * coin
details.append([coin, coin_num])
return total_coin_count, details
min_coin_count(4720, coin_list) ##(31, [[500, 9], [100, 2], [50, 0], [1, 20]])
C++
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
bool compare(int a, int b)
{
return a > b;
}
int main()
{
int n;
scanf("%d", &n);
int answer = 0;
int coins[] = {1, 100, 50, 500};
int length = sizeof(coins)/sizeof(coins[0]);
sort(coins, coins+4, compare);
for(int i = 0; i < length; ++i)
{
int balance = n % coins[i];
answer += (n/coins[i]);
printf("%d %d %d \n", coins[i], n/coins[i], balance);
n = balance;
}
printf("%d", answer);
return 0;
}
부분 배낭 문제 (Fractional Knapsack Problem)
- 무게 제한이 k인 배낭에 최대 가치를 가지도록 물건을 넣는 문제
- 각 물건은 무게(w)와 가치(v)로 표현될 수 있음
- 물건은 쪼갤 수 있으므로 물건의 일부분이 배낭에 넣어질 수 있음, 그래서 Fractional Knapsack Problem 으로 부름
- Fractional Knapsack Problem 의 반대로 물건을 쪼개서 넣을 수 없는 배낭 문제도 존재함 (0/1 Knapsack Problem 으로 부름)
Python
data_list = [(10, 10), (15, 12), (20, 10), (25, 8), (30, 5)]
5 / 30
- 가치/무게 : 무게단위당 가치
- 따라서 아래 코드에서 무게단위당 가치가 높은 것부터 앞으로오도록 람다함수를 코딩
def get_max_value(data_list, capacity):
data_list = sorted(data_list, key=lambda x: x[1] / x[0], reverse=True) ##reverse=True 코드 안넣으면 단위무게당 가치가 낮은것순으로 정렬
total_value = 0
details = list()
for data in data_list:
if capacity - data[0] >= 0:
capacity -= data[0] ##물건의 무게 data[0]
total_value += data[1] ##물건의 가치 data[1]
details.append([data[0], data[1], 1]) ## 마지막1은 해당 물건을쪼개지않고 100프로다 넣었음을표시하는 것
else: ##물건 쪼개기
fraction = capacity / data[0]
total_value += data[1] * fraction
details.append([data[0], data[1], fraction])
break
return total_value, details
get_max_value(data_list, 30) ##(24.5, [[10, 10, 1], [15, 12, 1], [20, 10, 0.25]])
C++
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
vector<pair<int, int>> data_list { {10,10}, {15,12}, {20,10}, {25,8},{30,5} };
bool compare(pair<int, int> a, pair<int, int> b)
{
return (a.second/a.first) > (b.second/b.first);
}
int main()
{
float data_weight;
cin >> data_weight;
sort(data_list.begin(), data_list.end(), compare);
float total_value = 0;
float fraction = 0;
for(auto it = data_list.begin(); it != data_list.end(); ++it)
{
if(data_weight - it->first >=0 )
{
data_weight -= it->first;
total_value += it->second;
}
else
{
fraction = data_weight / it->first;
total_value += (it->second * fraction);
break;
}
}
cout << total_value <<endl;
cout << fraction <<endl;
return 0;
}